
CSV data format, Occam’s Razor in Database
The simplest and most popular tool for storing and transferring data
Reading Time: 12 minutes
Post published on 11/02/2020 by Donata Petrelli and released with licenza CC BY-NC-ND 3.0 IT (Creative Common – Attribuzione – Non commerciale – Non opere derivate 3.0 Italia)
How much time we lose looking for objects that we don’t remember where we put them last time… from the black pumps for the evening or the red t-shirt for the gym to the mayonnaise in the fridge for the quick sandwich!
When we look for an object and we don’t find it, it is because this object isn’t placed in a database.
Extending the concept, archiving and manipulation of data has always been at the heart of every sector. From the scientific to the humanistic one, we cannot formulate theories and reach conclusions that are important for us if we do not start from the data and its analysis. This is why its management is fundamental.
Information Technology plays a key role in all this. Archiving large amounts of data (BigData), reading it, filtering it, ordering it, interrogating it is among its main activities and is the basis for technological development. For this reason, there are sophisticated software able to satisfy this function and, at the same time, numerous types of files that act as ‘containers’ for the data.
The problem arises when this data has to be extrapolated and managed within other programs. Often this is not possible due to the nature of the source files, proprietary files that are difficult to read except through their native program.
In the article we’ll talk about the simplest file that can act as a data container and that, for this feature, is suitable to act as a via for exporting and importing data between different programs, the CSV file format.
Database
From small to large realities there is a constant need to organize the data. Think for example of a library or a pharmacy … if they had not planned a system for the organization of their products, surely they would have closed down after a few days.
To satisfy this need there are the archives. The International Council of Archives defines them as:
<< The whole of the documents made and received by a juridical or physical person or organization in the conduct of affairs, and preserved>> (Multilingual Archival Terminology – archives – http://www.ciscra.org/mat/mat/term/64).
The archives therefore allow the organized collection of homogeneous objects, whether they are physical or digital products. In the previous examples are library directories or chemist’s chests of drawers. Archived objects are the data, i.e. the representation of a phenomenon or an elementary part of it when reality is more complex.
In computer science, the container for the organized collection of data is called Database. Inside a Database the data is organized in Tables whose number is equal to one (in the simplest cases) or in greater number than one in the most complex cases. In the latter case, these tables can be autonomous or have a logical relation between them. In this case, we talk about Relational Databases, while in the case of non-relational tables we talk about Flat Databases.
So a Database is a container of tables. If there is only one table, it will be the Database itself. The data is contained in tables, which in turn have a definite structure. A table is in fact organized in rows and columns like a matrix. In a table there must be at least one row and each row is named record.
Within a record there is information divided into individual data or homogeneous groups. Each individual data (or homogeneous group of data) is called a record field. The columns identify the fields and the rows identify the records. In turn, the data contained in the field may be of a different nature: text, number, static or dynamic image, sounds, etc. Depending on the nature, there is the corresponding data format.
From theory to practice the passage is short. In fact, a simple table in an Excel spreadsheet is already a Database!
Let’s take an example. Suppose we have to describe the weather situation in a city at a certain time. In order to do this we need to know the value of some fundamental parameters such as weather, temperature, winds, precipitation, humidity, visibility… and to be able to store them for example hour by hour in the period of observation. To do this we can use an Excel table as in the following figure where in the first row there are the column headings (field names) and in the following rows the set of hourly data (records).
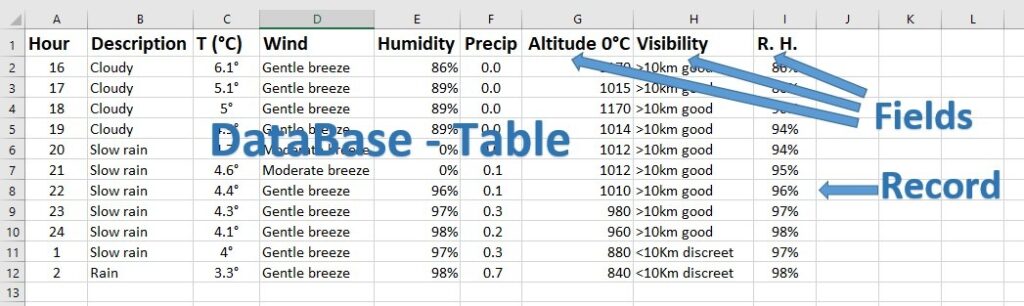
Even a simple database like this is useful for processing data. In addition to archiving data, a database allows us to sort, filter, query, analyze and make calculations, i.e. to perform operations necessary to extract precious information from data.
What Database?
Given the strategic importance of databases, an entire ecosystem has developed over time that includes not only a wide choice of hardware and software solutions but also a wide range of professionals.
Depending on the domain, there are experts for that.
At hardware level there are:
- Database Manager, an active manager that takes care of the ‘health’ of the database and its continuous improvement in terms of hardware, security, use and data source;
- Data Architect who designs information systems, flows and data repositories as needed.
At software level, there are data experts such as:
- Data Engineer who takes care of the availability, quality and usability of data for those who use it;
- Data Analyst who analyzes and interprets the data provided to transform it into useful information;
- Data Scientist, an advanced data analyst that manages the data from a strategic point of view for its use during the decision-making process.
In addition, depending on the role covered, specific hard skills are required such as:
- MySQL, Oracle
- SQL, XML
- Java, Python, Kafka, Hive or Storm
- Microsoft Excel, Microsoft Access, SharePoint and SQL databases
- R or Python to implement mathematical models and Artificial Intelligence algorithms
From here we can already understand the complexity and vastness of the Database world. Thanks to them were born real empires in computer science. Oracle Corporation based in Silicon Valley, today a multinational company in the IT sector, has become very famous in the world with its top product, the Oracle Database!
The problem arises when we have to be able to archive data by ourselves. In fact, independently of our profession or role, we often and for various reasons need to store data in order to find useful answers faster… if only to find the T-shirt in the drawers or the mayonnaise jar in the fridge
As Confucius says “Do not use cannons to kill mosquitoes” … so, in these cases, we must find a simple solution that does not require sophisticated software or the support of professionals.
Yes… but which one?
CSV file
A simple archiving tool, accessible to everyone, even non-programmers, is the CSV file.
A CSV file is a simple TXT text file but with special symbols inside that determine its structure and make it perfect to represent data in tabular format … it is therefore a flat database containing structured data.
CSV is an acronym for Comma-Separated Values (values separated by commas) which indicates its peculiarity: in this text file every data is separated by a comma or another character. Being a text format, .csv files can be opened with any text file management program such as, for example, the Microsoft Notepad program present in any Microsoft Windows distribution.
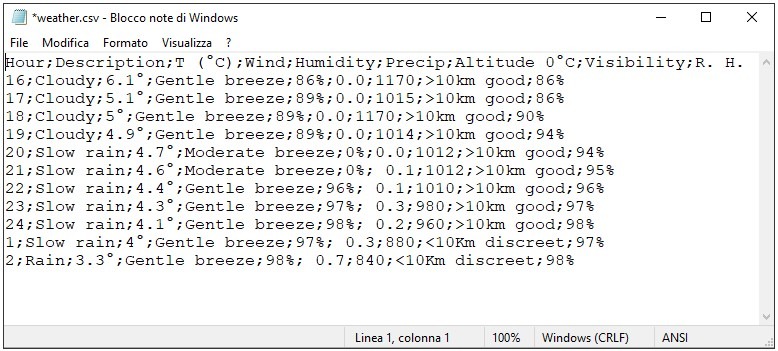
Once opened a CSV file we will notice the peculiarity of this text file that appears as a list of data with conventional characters indicating how this data should be managed or interpreted. To get a precise idea of what they are, let’s take the example of meteorological data and convert the Excel table in CSV format. We get:
Hour;Description;T (°C);Wind;Humidity;Precip;Altitude 0°C;Visibility;R. H.
16;Cloudy;6.1°;Gentle breeze;86%;0.0;1170;>10km good;86%
17;Cloudy;5.1°;Gentle breeze;89%;0.0;1015;>10km good;86%
18;Cloudy;5°;Gentle breeze;89%;0.0;1170;>10km good;90%
19;Cloudy;4.9°;Gentle breeze;89%;0.0;1014;>10km good;94%
20;Slow rain;4.7°;Moderate breeze;0%;0.0;1012;>10km good;94%
21;Slow rain;4.6°;Moderate breeze;0%; 0.1;1012;>10km good;95%
22;Slow rain;4.4°;Gentle breeze;96%; 0.1;1010;>10km good;96%
23;Slow rain;4.3°;Gentle breeze;97%; 0.3;980;>10km good;97%
24;Slow rain;4.1°;Gentle breeze;98%; 0.2;960;>10km good;98%
1;Slow rain;4°;Gentle breeze;97%; 0.3;880;<10Km discreet;97%
2;Rain;3.3°;Gentle breeze;98%; 0.7;840;<10Km discreet;98%In this example the character that separates one data from another within each row is the comma (;), the single data is the value of the table field, the first row is the one that identifies the field names, the next rows the stored data records. By saving this particular table in .CSV format we obtained a Flat Database … simple right?
Today the CSV format is the most diffused format for the import and export data in spreadsheets or databases.
In CSV format there are no specifications for
- character encoding
- the convention to indicate the end of the line
- the character to use as a separator between fields (in the Anglo-Saxon world normally is a comma, in Italy it is the semicolon because of the use of the comma in decimal numbers)
- conventions to represent dates or numbers as all values are considered as simple text strings.
These details may need to be specified by the user each time you import or export data in CSV format into a program, such as during a spreadsheet wizard.
The format conversion
Before importing data we must pay attention to the content of the text files. In the American format, for example, the numbers in the text will use the decimal point (.) instead of the comma (,) as in the European format … and this will cause problems during the conversion.
To remedy this, simply open the file with Notepad (or any other similar program) and automatically replace the dot (.) character with a comma (,). However, since in many CSV files the data is also separated by the comma (,), we must remember to replace the comma (,) with a semicolon (;) first. First replace the commas (,) with semicolons (;) then replace the dots (.) with commas (,) in that order. These operations can be easily done via the “Edit” menu and by selecting the “Replace” option. Once this operation is done, we proceed with saving the data by overwriting it and keeping the same name as the CSV file. At this point the text file is ready to be imported.
Import data via VBA
Automating the data reading and importing is useful to gain time and to eliminate potential problems and errors that may occur during the importing process.
When the data is in a format different from our international settings it is not always easy to proceed with the preliminary operations seen before on the text file. Sometimes it is necessary to manage data directly from VBA code within the application (Excel).
The VBA code to read a CSV file like this
is as follows:
Sub OpenFileCSV(ByVal FP As String)
On Error GoTo ErrorManager
Dim R As Integer
Dim L As String
Dim FN As Integer
Dim LI() As String
FN = FreeFile
Open FP For Input As #FN
R = 0
Do While Not EOF(FN)
Line Input #FN, L
LI = Split(L, ";")
ActiveCell.Offset(R, 0).Value = LI(0) ‘Hour
ActiveCell.Offset(R, 1).Value = LI(1) ‘Description
ActiveCell.Offset(R, 2).Value = LI(2) 'T (° C)
ActiveCell.Offset(R, 3).Value = LI(3) ‘Wind
ActiveCell.Offset(R, 4).Value = LI(4) 'Humidity
ActiveCell.Offset(R, 5).Value = LI(5) 'Precip
ActiveCell.Offset(R, 6).Value = LI(6) ' Altitude 0°C
ActiveCell.Offset(R, 7).Value = LI(7) ' Visibility
ActiveCell.Offset(R, 8).Value = LI(8) 'R.H.
R = R + 1
Loop
Close #FN
Exit Sub
ErrorManager:
MsgBox “Loading error!”
End SubLI = Split(L, “;”) separate the text line L using the symbol “;” as separator. This will result in single portions of text corresponding to the various fields and each of them will be added as an element of the LI vector.
The following commands fill the cells with the various parts of the vector. For example Hour, which is the first field, is contained within the first element of the vector LI(0), since vectors always begin with the number 0. The second field is Description and its value is contained inside the second element of the vector which is LI(1), and so on for the others. At the end of the procedure the various fields will be inserted correctly in the different cells. This code contains within it the manual decoding of the fields and we must therefore know their structure.
However, it is not always easy to correctly decipher the nature of the data to be imported or we would like to proceed faster to do so. In addition, automating too much can sometimes cause potential errors, as well as complicating the code without taking proportionate advantage.
To solve the previous problems you could directly use a web data extraction software able to transform the unstructured data present in the web, usually in HTML format, into metadata that can be stored and analyzed locally in a database
… this topic opens different scenarios and reflections … to be treated in a new article 😉
Beyond the CSV … XML
You might ask me now: in more complex cases of structured data can you still use CSV? or is a more powerful tool like XML better?
The XLM file was created for purposes very different from ours. It is a meta-language of markup, that is a language that allows to define new languages suitable to describe structured documents. With the word “documents” we mean not only web pages or texts but also everything that contains information. This is why XML is now also used a lot as a data archive and tool for exporting data between different database management systems (DBMS).
XML is a text file that contains a set of tags, attributes and text that follow well-defined syntax rules. It is characterized by a hierarchical structure, assigned to components called elements. Each element is therefore a logical component of the document and may contain other elements (sub-elements) or text.
An example of an XML document is as follows:
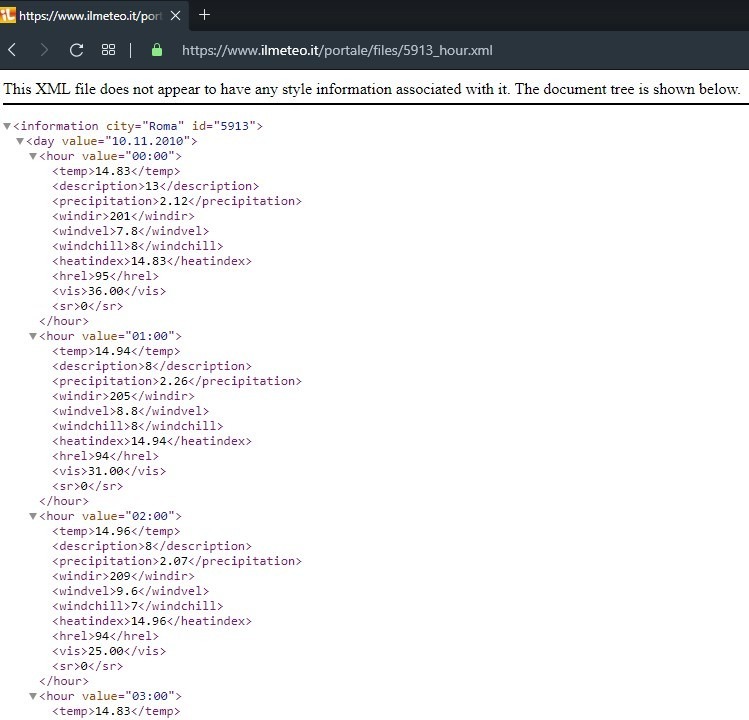
The definition of a document is done through the use of tags that are unlimited and not defined as for the HTML format. With XML you can always define new tags, depending on your needs. This makes XML one of the most powerful and flexible tools for the creation, memorization and distribution of digital documents.
However, its rigorous syntax does not make it a language of simple reading and writing. In fact, all XML files must be subject to a fundamental principle: they must be well formed. There are a series of strict rules to follow or the resulting document will be invalid.
We could compare this principle to that of the orthographic and grammatical accuracy of a language. When we decide to use a language to transmit information or to communicate with people, we must evaluate its complexity, both in logical and grammatical terms. Choosing a simpler and more immediate language is often a more appropriate choice to communicate with as many people as possible.
In the same way this makes us think about using XML as a tool for exchanging data between two sources. Is it really the most suitable choice if the same type of operation can be done more easily and quickly with CSV?
CSV, Data and Big Data
In addition to the complexity of the structure of a document, what we have to consider when we talk about databases is their size, the amount of data.
Certainly in this article we are not discussing great amounts of data like Big Data. In these situations you will need to work with real database management software. Here we are dealing with small and controllable files.
In these cases we have seen that CSV is the tool that suits the data transfer best. The question we have to ask ourselves now is: what is its limit? How many records, therefore rows, can I manage with CSV?
There are no rules or answers already established. It is up to us to find a logic on the basis of which we can determine how far CSV should be used for storing and exporting data.
The most popular tool in the world, both private and professional, for data collection and processing is Excel. Therefore we can consider the “capacity” of a normal Excel file and, consequently, the limit for the CSV could be the one that can open Excel. The question then becomes: what is the limit of an Excel file? How many rows can it manage?
Up to version 2007 Excel manages 65,535 rows and 256 columns. From 2010 onwards, it handles up to over 1,000,000 rows … which is no small thing! So let’s try to import 65,535 rows from a CSV file, containing different test data, into Excel. We get:
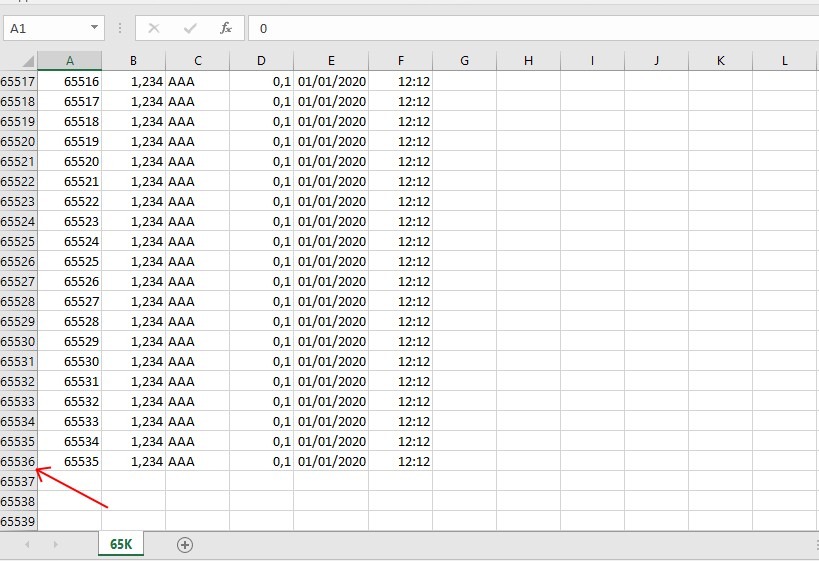
We do even more and import 1,048,575 lines, the maximum content from Excel.
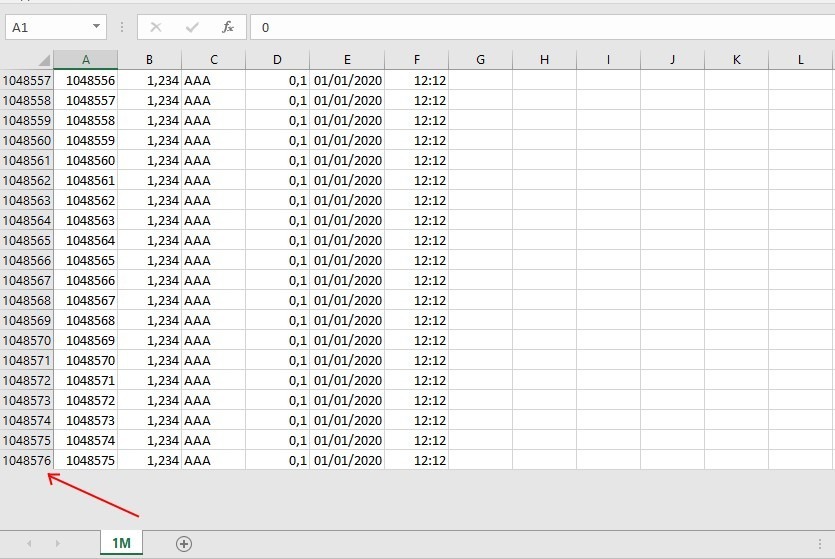
It follows that thanks to a CSV file we are able to manage 1,048,575 records … in practice we could archive the entire population of Köln! A surprising result that comes very close to the concept of Big Data and that once again legitimises the use of CSVs in data exchange operations.
The problem is postponed to when you exceed the number of lines that Excel can open. But these cases are far from ordinary business or personal problems.
Conclusion
In a data driven world like ours it is essential to know how to work with it. In fact, data is the new currency in the modern economy. Knowing how to take data, process it, manipulate it and finally predict it allows us an enormous competitive advantage. That’s why having the right tools and knowing the methodologies for their treatment is essential today.
In the absence of Database specific tools, the CSV responds appropriately to the most common data processing needs. Its simplicity and, at the same time, its powerfulness make it today the most widely used tool for data management and transfer.
As Occam’s Razor says… simplicity always wins!
What we’ve seen
- Database
- File Format
- CSV
- XML
- Importing and exporting data
- Converting data
- VBA programming
If you want to learn more about the topics covered in the article, you can find them in the book at the following link:
https://www.donatapetrelli.com/books/
where the entire chapter 2 is dedicated to data, its availability and management.
If you found this article interesting and useful I will be happy if you want to share it ?


